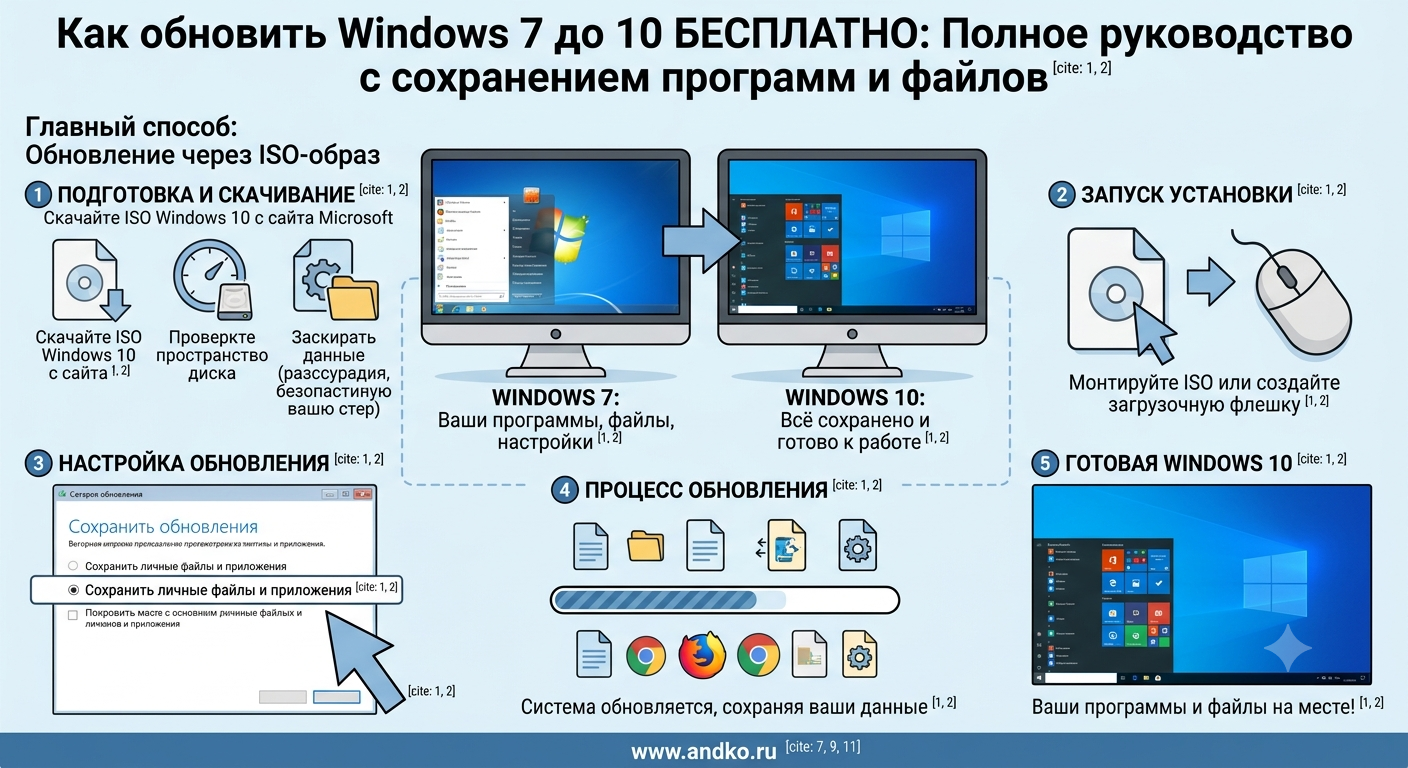
Проблема
Переход от junior-администратора к middle это не просто увеличение количества знакомых команд, а смена подхода к работе. Junior обычно выполняет чётко поставленные задачи, следуя инструкциям. Middle же должен самостоятельно проектировать решения, прогнозировать последствия изменений, находить коренные причины проблем и обеспечивать надёжность инфраструктуры. Однако чёткого списка требований к middle-специалисту в Linux нет: в каждой компании ожидания различаются. В этой статье я обобщу реальный опыт, который позволяет администратору уверенно чувствовать себя на позиции middle, от глубинного понимания системы до навыков автоматизации и общения с коллегами.
Решение
Опыт администрирования Linux на уровне middle это совокупность технических и нетехнических компетенций. В этой статье я представлю структурированный список того, что нужно знать и уметь, разделённый на категории. Статья не содержит пошаговых инструкций, но включает ссылки на официальные источники для углублённого изучения, а также практические советы, основанные на реальных инцидентах.
Пошаговый разбор компетенций
1. Глубокое понимание загрузки системы и управления процессами
Middle-администратор должен не просто уметь перезагрузить сервис, а понимать, что происходит на всех этапах загрузки и как процессы взаимодействуют с ядром.
-
initramfs и загрузчик GRUB: умение восстановить систему при повреждении GRUB, изменить параметры ядра через
/etc/default/grubи пересобрать initramfs. Официальная документация: GNU GRUB Manual , Debian initramfs. -
Systemd (или SysVinit): знание не только
systemctl, но и юнитов, таймеров, целевых состояний,journalctlс фильтрами,systemd-analyzeдля поиска узких мест. systemd Documentation . -
Управление процессами: сигналы (SIGTERM, SIGKILL, SIGHUP), управление приоритетами (
nice,renice), анализ открытых файлов (lsof,fuser). Linux manual pages . - Планировщик задач: cron и systemd timers, умение отлаживать невыполнение задач, проверка прав и переменных окружения.
2. Администрирование файловых систем и дисков
Middle должен уметь работать с различными файловыми системами, устранять проблемы с местом и целостностью данных.
-
Типовые ФС: ext4, XFS, Btrfs, ZFS знать особенности, когда что применять, уметь расширять разделы без остановки, настраивать монтирование через
/etc/fstab. XFS Documentation , ZFS on Linux . - LVM: управление физическими томами, группами томов, логическими томами; уменьшение/увеличение томов; snapshot-ы. LVM Howto .
- RAID: понимание разницы между программным (mdadm) и аппаратным RAID, диагностика отказавших дисков, замена в горячем режиме. mdadm documentation .
-
Мониторинг дисков:
iostat,iotop,smartctl(S.M.A.R.T.), выявление медленных дисков, прогнозирование отказа. smartmontools .
3. Сетевое администрирование и диагностика
Опытный администратор не боится «лезть в сеть» на любом уровне от физического до приложений.
- Настройка интерфейсов: статическая и динамическая настройка (Netplan, NetworkManager, ifupdown), мосты (bridge), VLAN, bonding/teaming. Netplan documentation .
-
Диагностика:
ip(вместо ifconfig),ss(вместо netstat),tcpdump,tshark,nmap,mtr. Умение читать выводtcpdumpи фильтровать по портам, IP, флагам TCP. - Маршрутизация и iptables/nftables: понимание таблиц (filter, nat, mangle), цепочек, правил. Настройка NAT, порт-форвардинга, ограничений. nftables wiki .
- Основы BGP/OSPF (для сетевых инженеров, но middle-администратор должен хотя бы понимать концепции динамической маршрутизации).
4. Безопасность и управление доступом
Безопасность это не установка fail2ban, а системный подход.
-
SSH: настройка ключей, отключение паролей, ограничение доступа по пользователям/группам, настройка ssh-агента, использование
sshuttleдля проксирования. -
sudo и права: гранулярная настройка sudo через
/etc/sudoers.d/, ограничение по командам. - SELinux или AppArmor: умение диагностировать ошибки (audit.log), временно отключать, создавать политики. SELinux Project , AppArmor .
- Аудит и логи: настройка auditd для отслеживания изменений файлов, логирование в централизованную систему (ELK, Graylog).
- Fail2ban: настройка под нестандартные сервисы (например, для nginx, vsftpd, postfix). Fail2ban Documentation .
5. Автоматизация и скрипты
Middle-администратор не должен делать руками то, что можно автоматизировать. Владение хотя бы одним языком скриптования обязательно.
-
Bash: написание функций, обработка ошибок (
set -euo pipefail), работа с getopt, использованиеjqдля JSON. Bash Reference Manual . -
Python: умение написать скрипт для парсинга логов, взаимодействия с API, простого веб-сервера. Рекомендуется знать модули:
os,sys,subprocess,requests,argparse. - Ansible (или аналоги): написание плейбуков, ролей, работа с переменными, vault. Ansible Documentation .
-
Управление конфигурациями: умение использовать Git для версионирования конфигураций (например,
/etcв git), понимание CI/CD для доставки изменений.
6. Виртуализация и контейнеризация
Современный middle-администратор обязан уметь работать с популярными платформами виртуализации и контейнеризации.
-
KVM/libvirt: создание и управление виртуальными машинами через
virsh, virt-manager, настройка сетей (NAT, bridge). Libvirt Documentation . - Docker/Podman: сборка образов (Dockerfile), управление контейнерами, сети, тома. Понимание разницы между Docker и Podman, использование docker-compose/podman-compose. Docker Docs , Podman .
-
Kubernetes (для middle желательно базовое знакомство): понимание подов, сервисов, деплойментов, использование
kubectl. - Proxmox VE (как пример гипервизора): умение разворачивать, настраивать кластер, хранилища, бэкапы. Proxmox Documentation .
7. Мониторинг и логирование
Без мониторинга администратор работает вслепую. Middle должен уметь настраивать системы мониторинга и анализа логов.
- Prometheus + Grafana: установка, настройка экспортёров (node_exporter, blackbox_exporter), написание запросов (PromQL), создание дашбордов. Prometheus Docs .
- Zabbix: создание шаблонов, триггеров, настройка обнаружения (LLD). Zabbix Documentation .
- ELK/OpenSearch: настройка Filebeat для сбора логов, базовые запросы в Kibana.
8. Резервное копирование и восстановление
Настоящий опыт проверяется не в штатной работе, а при восстановлении после сбоя.
- Стратегия 3-2-1: умение реализовать на практике.
- Инструменты: знание как минимум одного решения для бэкапа (Borg, Restic, Veeam, Proxmox Backup Server). BorgBackup , Restic .
- Восстановление: практика восстановления всей системы из бэкапа (bare-metal), восстановление отдельных файлов/баз данных.
- Снапшоты файловых систем: LVM-снапшоты, ZFS-снапшоты, Btrfs-снапшоты умение создавать и восстанавливать.
9. Поиск и устранение неисправностей (troubleshooting)
Middle отличается от junior умением структурированно подходить к проблеме и использовать все доступные инструменты.
- Методика: определение границ проблемы (локально/удалённо), сбор информации (логи, метрики, трассировка), формулировка гипотез, проверка, фиксация.
-
Инструменты диагностики:
strace,ltrace,perf,sysdig,gdb(базово). strace manual . -
Анализ логов: умение эффективно работать с
grep,awk,sed,lessдля быстрого поиска. - Кейсы: знание типичных проблем (высокий load average, полный диск, проблемы с DNS, таймауты сети) и способов их диагностики.
10. Коммуникация и документация
Технические навыки бесполезны, если администратор не умеет работать в команде и документировать решения.
- Документирование: ведение wiki (Confluence, BookStack, Markdown-репозитории). Чёткое описание архитектуры, процедур восстановления, сетевых схем.
- Инструменты для совместной работы: Git, Mattermost/Slack, системы тикетов (Jira, Redmine, Zammad).
- Soft skills: умение объяснить технические проблемы нетехническим руководителям, аргументировать необходимость изменений, работать в режиме «on-call».
Что нужно уметь делать руками (практический чек-лист)
Ниже приведён список задач, которые middle-администратор должен выполнять уверенно, без обращения к гайдам:
| Область | Конкретные задачи |
|---|---|
| Система | Настроить GRUB для загрузки с другого ядра; восстановить систему после повреждения /etc/fstab; изменить размер корневого раздела на лету (LVM). |
| Сеть | Настроить маршрутизацию между двумя интерфейсами; добавить VLAN на интерфейс; диагностировать потерю пакетов через mtr и tcpdump. |
| Безопасность | Настроить SELinux для веб-сервера на нестандартном порту; создать политику sudo для группы админов с ограничением команд. |
| Автоматизация | Написать bash-скрипт, который проверяет свободное место и отправляет уведомление в Telegram; создать ansible-плейбук для установки и настройки nginx. |
| Контейнеризация | Собрать образ контейнера с приложением и запустить его с пробросом портов; настроить docker-compose для связки app+db. |
| Мониторинг | Добавить новый экспортёр в Prometheus и создать дашборд в Grafana; настроить алерт на загрузку CPU. |
| Бэкапы | Восстановить один файл из бэкапа, созданного Borg; создать снапшот ZFS и смонтировать его для восстановления. |
| Troubleshooting | Найти процесс, который пишет на диск более 50 МБ/с; выяснить причину, почему не запускается systemd-юнит. |
Устранение распространённых «мифов» о middle
| Миф | Реальность |
|---|---|
| Middle должен знать всё о Linux | Невозможно знать всё. Важно уметь быстро находить информацию в официальной документации и понимать принципы работы. |
| Middle = 5 лет стажа | Стаж важен, но ещё важнее разнообразие задач. Человек с 2 годами, но работавший в сложной инфраструктуре, может быть middle. |
| Сертификаты (RHCE, LPIC) обязательны | Они помогают, но не заменяют реальный опыт. Middle часто не имеет сертификатов, но решает сложные задачи. |
| Middle не работает руками, только архитектура | Практика показывает, что middle активно работает с консолью, но при этом проектирует решения и учит джуниоров. |
Итог
Опыт администрирования Linux на уровне middle это не просто сумма знаний, а системное мышление, умение диагностировать сложные проблемы, автоматизировать рутину и эффективно взаимодействовать с командой. В этой статье я выделил ключевые компетенции: от глубокого понимания загрузки и сетей до владения инструментами мониторинга, контейнеризации и автоматизации. Критически важно не только знать теорию, но и уметь применять её на практике, восстанавливая системы после сбоев и документируя решения.
Для дальнейшего роста стоит углубляться в архитектуру распределённых систем, изучать Kubernetes, облачные провайдеры (AWS, Yandex Cloud), а также практиковаться в написании сложных скриптов и плейбуков. Постоянное чтение официальной документации (например, kernel.org, Red Hat Customer Portal, Debian Handbook) и участие в сообществах (например, Linux.org) помогают оставаться в тонусе.